
I would like to thank John Baez one more time for his heroic efforts in educating the public. I learn a lot from his website. The tutorial material below is from his July 2022 diary. I added commentary.
Quantitative measure of information
Information we get when we learn an event of probability p has happened: 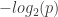

Let me explain this in more familiar terms. Compare 1 bit of computer memory to 1 byte of computer memory. Which one can store more information? Obviously, 1 byte can store more information than 1 bit. The word “probability” confuses us. How many different ways can you write into 1 byte (8 bit) memory? The answer is 

The actual stored information is one of those states, say (0,1,0,0,0,0,0,0). Other states are possibilities. Then it is natural to ask “what is the expected (average) amount of information contained in a given state of the system?” That’s quantified as Shannon entropy.
Shannon entropy

When we apply the formula to 1 byte of computer memory, assuming each one of those 256 arrangements (states) has equal probability (1/256) we get H=8 (bits of information). This is a trivial example. In general, the probability of each state can be different. Don’t forget the logical rule: sum of all 
If a highly likely event occurs, we learn very little information. If an event with probability 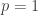
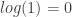
The information content (Shannon information) of an event increases as the probability of an event decreases.
One of the popular interpretations of Shannon entropy is uncertainty. It is said that the Shannon entropy quantifies the amount of uncertainty involved in the outcome of a random process. For example, identifying the outcome of a fair coin flip (with two equally likely outcomes) provides less information (lower entropy) than specifying the outcome from a roll of a die (with six equally likely outcomes). Therefore, there is higher uncertainty in the die roll compared to the coin flip.
I know, this subject gets confusing very quickly. One more interpretation. We can also say that the Shannon entropy is the amount of information required to describe a system. It gets harder to describe a system when the variability (number of states) of the system is larger.
